Query Processing In Clickhouse
ClickHouse is easily one of the fastest OLAP databases on the face of this planet. I have had the fortune of working on it at different stints. This is my attempt to best summarize my understanding of it.
This post is latest as on 835afe1f342.
Introduction
ClickHouse is a columnar, vectorized OLAP database written in C++. We will take an example read query, and look at how the query is processed.
Consider this SQL as the example query:
-- Schema
CREATE TABLE purchases
(
`dt` DateTime,
`customer_id` UInt32,
`total_spent` Float32
)
ENGINE = MergeTree
ORDER BY dt;
-- Read Query
SELECT
floor(total_spent) AS s,
count(*) AS n,
bar(n, 0, 350000, 50)
FROM purchases
GROUP BY s
ORDER BY s ASC
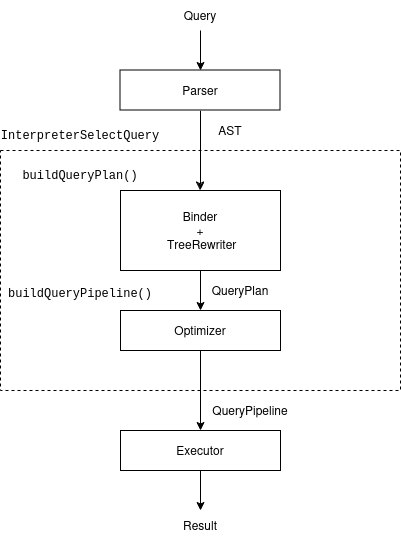
When we run the SELECT query, at a high-level the following happens:
- The ClickHouse server receives the query and calls
executeQuerywhich executes the query. - The query string is parsed by the ClickHouse Parser to create an Abstract Syntax Tree(AST) representation of the query.
- An Interpreter is created to interpret this AST by doing the following:
- Creates a logical query plan by rewriting the AST for binding symbols with objects from the catalog, applying settings, and making logical query optimizations.
- Creates the physical query plan by applying optimizations to the logical query plan.
- An execution graph is created from this physical query plan.
- An executor executes the execution graph in multiple threads(depending on the settings).
Query processing can be broken down broadly into the following stages:
- Parser
- Building Query Plan
- Building Query Pipeline
- Executing the query.
Let’s look at the data structures used. We will then see how their are built in future posts.
AST
The AST data structure is a tree.
Each type of AST subclasses IAST and describes data specific to the grammar. Eg: ASTSelectQuery for a Select Query.
class IAST : public std::enabled_shared_from_this<IAST> , public TypePromotion<IAST>
{
public:
ASTs children;
};
The AST for our query looks something like:
┌─explain─────────────────────────────────────┐
│ SelectWithUnionQuery (children 1) │
│ ExpressionList (children 1) │
│ SelectQuery (children 4) │
│ ExpressionList (children 3) │
│ Function floor (alias s) (children 1) │
│ ExpressionList (children 1) │
│ Identifier total_spent │
│ Function count (alias n) (children 1) │
│ ExpressionList (children 1) │
│ Asterisk │
│ Function bar (children 1) │
│ ExpressionList (children 4) │
│ Identifier n │
│ Literal UInt64_0 │
│ Literal UInt64_350000 │
│ Literal UInt64_50 │
│ TablesInSelectQuery (children 1) │
│ TablesInSelectQueryElement (children 1) │
│ TableExpression (children 1) │
│ TableIdentifier purchases │
│ ExpressionList (children 1) │
│ Identifier s │
│ ExpressionList (children 1) │
│ OrderByElement (children 1) │
│ Identifier s │
└─────────────────────────────────────────────┘
Logical Query Plan
The logical query plan is built by performing the following:
- Rewriting the AST by applying logical query optimizations. Eg: Predicate Pushdown, Constant Folding, etc.
- Applying AST-level settings like
count_distinct_implementation. - Binding all symbols/identifiers to their corresponding objects from the database catalog.
The logical query plan - QueryPlan is a tree with each node being a IQueryPlanStep. Each clause is in the query plan is an object of IQueryPlanStep. Eg: JoinStep,SortingStep.
class QueryPlan
{
struct Node
{
QueryPlanStepPtr step;
std::vector<Node *> children = {};
};
// Optimizes the logical query plan
void optimize(const QueryPlanOptimizationSettings & optimization_settings);
// Builds the physical query plan
QueryPipelineBuilderPtr buildQueryPipeline(
const QueryPlanOptimizationSettings & optimization_settings,
const BuildQueryPipelineSettings & build_pipeline_settings);
}
The nodes in the query plan are also connected with data streams.
// Logical data stream containing description of the stream
class DataStream {};
using DataStreams = std::vector<DataStream>;
class IQueryPlanStep
{
public:
/// Add processors from current step to QueryPipeline.
virtual QueryPipelineBuilderPtr updatePipeline(QueryPipelineBuilders pipelines, const BuildQueryPipelineSettings & settings) = 0;
protected:
DataStreams input_streams;
std::optional<DataStream> output_stream;
}
The logical query plan for our query looks something like this:
┌─explain──────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY [lifted up part])) │
│ Sorting (Sorting for ORDER BY) │
│ Expression (Before ORDER BY) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ ReadFromPreparedSource (Read from NullSource) │
└──────────────────────────────────────────────────────────────┘
Physical Query Plan
The physical query plan is called Query Pipeline in ClickHouse.
To translate the logical query plan into a Query Pipeline, QueryPlan::buildQueryPipeline is called.
This performs optimizations on the logical query plan.
After optimizations are done, each step is translated into one or more sets of processors using IQueryPlanStep::updatePipeline in an inorder traversal of the tree.
The query pipeline is a tree with each node being a IProcessor. Each processor represents a stage in the query execution. They are closely linked to the actual execution. Eg: Depending on the specifics, SortingStep is transformed to PartialSortingTransform, MergeSortedTransform and MergeSortingTransform in the query pipeline.
class QueryPipeline {
private:
std::shared_ptr<Processors> processors;
InputPort * input = nullptr;
OutputPort * output = nullptr;
};
class IProcessor
{
protected:
InputPorts inputs;
OutputPorts outputs;
public:
enum class Status
{
NeedData,
PortFull,
Finished,
Ready,
Async,
ExpandPipeline,
};
virtual Status prepare(const PortNumbers & updated_input_ports, const PortNumbers & updated_output_ports);
virtual void work();
virtual int schedule();
virtual Processors expandPipeline();
}
IProcessor::Status is used to signal whether data should be pushed to a processors’ port or not. This is used while executing the query. We will look at this in detail in a future post about the query execution.
The query pipeline for our query looks something like:
┌─explain────────────────────────────────────┐
│ (Expression) │
│ ExpressionTransform │
│ (Sorting) │
│ MergingSortedTransform 16 _ 1 │
│ MergeSortingTransform _ 16 │
│ LimitsCheckingTransform _ 16 │
│ PartialSortingTransform _ 16 │
│ (Expression) │
│ ExpressionTransform _ 16 │
│ (Aggregating) │
│ Resize 1 _ 16 │
│ AggregatingTransform │
│ (Expression) │
│ ExpressionTransform │
│ (ReadFromPreparedSource) │
│ NullSource 0 _ 1 │
└────────────────────────────────────────────┘
Now that we have looked at the data structures involved in query processing, we will look at how these data structures are built and used in the next post.